Streamlit RAG based Chatbot

on this page
Introduction
Recently I participated in an LLM hackathon at work. The requirements were quite flexible, and I basically ended up building a RAG pipeline over some corporate documents. I felt lazy, and did not want to build a frontend, nor did I want anything very complex.
What is streamlit?
Enter, Streamlit! Its a really cool python library that lets you build UI for your apps blazingly fast, and honestly while looking very sleek. And its crazy how fast you can get things started with it. But before we can start on our UI, lets see how we can make a really simple, and efficient RAG pipeline using Langchain, Chroma, and Cohere.
Building the RAG Pipeline
Knowledge Base
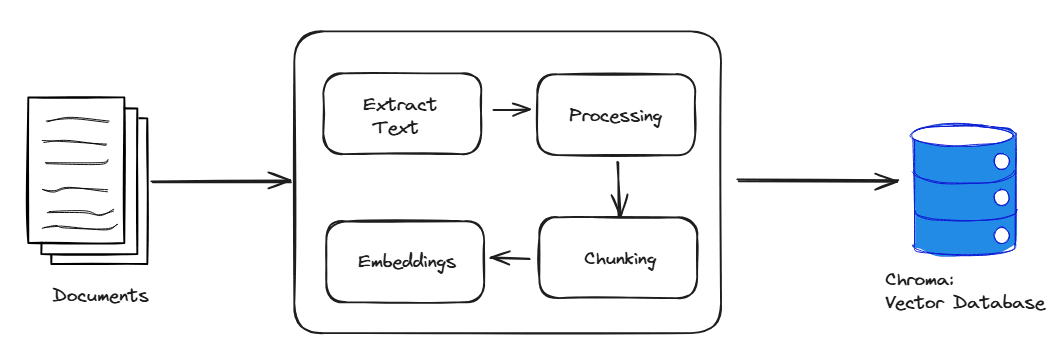
First of all, collect your knowledge base. Get all your documents and put them in one place. Now lets get started with the processing (white space removal, punctuation removal etc.). After applying any processing(optional), we will split the documents into small chunks for easy indexing, and retrieval. Now we will embed them into a chroma instance with sentence-bert as our embeddings model.
from langchain_chroma import Chroma
from langchain_community.embeddings.sentence_transformer import SentenceTransformerEmbeddings
CHROMA_DIR = "./.chroma"
SBERT_MODEL_NAME = "all-MiniLM-L6-v2"
embedding_function = SentenceTransformerEmbeddings(model_name=SBERT_MODEL_NAME)
chroma = Chroma(persist_directory=CHROMA_DIR, embedding_function=embedding_function)import os
from utils import flatten
from langchain_community.document_loaders import UnstructuredFileLoader
from unstructured.cleaners.core import clean_extra_whitespace
from langchain.text_splitter import RecursiveCharacterTextSplitter
from vector_store import chroma
DOCUMENTS_DIR = "./documents"
# Chunking parameters
CHUNK_SIZE = 1000
CHUNK_OVERLAP = 200
def get_chunks_from_file(path : str, chunk_size = CHUNK_SIZE, chunk_overlap=CHUNK_OVERLAP):
splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
loader = UnstructuredFileLoader(path, post_processors=[clean_extra_whitespace])
return loader.load_and_split(splitter)
chunks = flatten([
get_chunks_from_file(os.path.join(DOCUMENTS_DIR, file))
for file in os.listdir(DOCUMENTS_DIR)
if file.endswith(".docx") or file.endswith(".pdf") or file.endswith(".txt")
])
chroma.add_documents(chunks)This figure explains this all pretty well.
RAG Chain
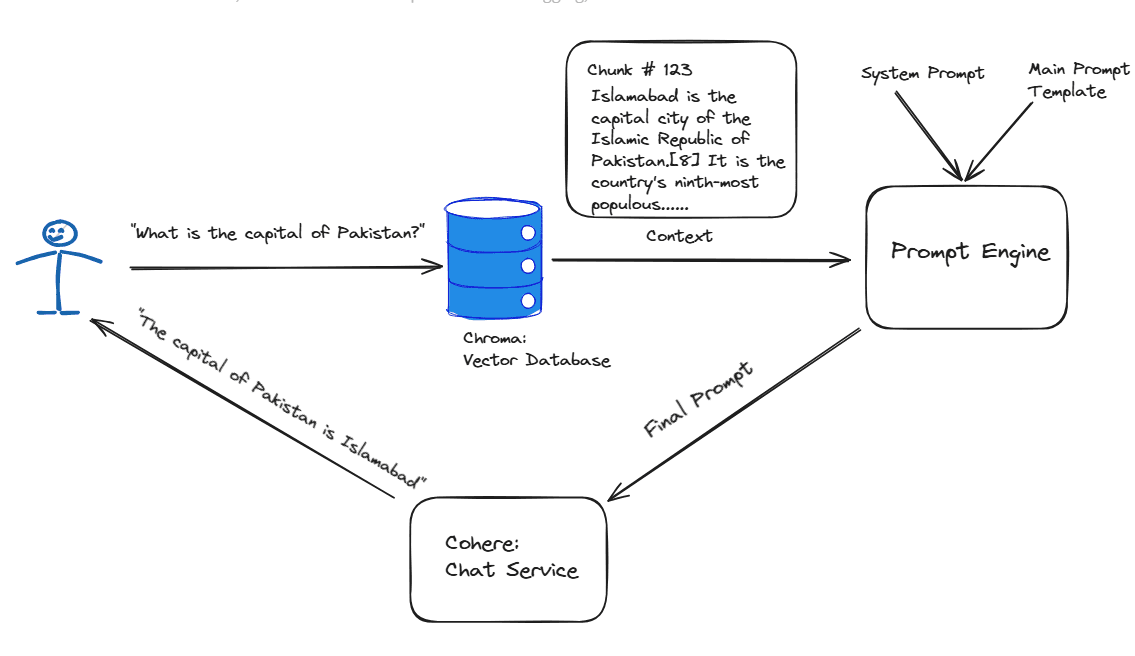
Now we can query the chroma instance in a langchain chain object. The fetched document chunks, and the provided prompts (question, system message etc) are formatted into a final prompt using a prompt template.
from vector_store import chroma
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from system_message import system_message
message = """
Answer this question using the provided context only.
{question}
Context:
{context}
"""
prompt = ChatPromptTemplate.from_messages([("system", system_message),("human", message)])
retriever = chroma.as_retriever(
search_type="similarity",
search_kwargs={"k": 2},
)
chain = {"context": retriever, "question": RunnablePassthrough()} | promptNotice how there's a bit of prompt engineering. Specifically, there's a system message which helps guide the overall setting of the chatbot.
Cohere for Text Generation
Now that we are able to query the instance to get similar documents, and constructed a prompt from them, we need a text generation service to actually produce the final answer. For this I used cohere which has a pretty decent free tier if I do say so myself. Anyways, putting this in our system looks something like this.
from langchain_cohere import ChatCohere
from dotenv import load_dotenv
from chain import chain
import os
load_dotenv()
llm = ChatCohere(
cohere_api_key=os.getenv("COHERE_API_KEY")
)
def response_generator(query):
prompt = chain.invoke(query)
return llm.stream(prompt)This is what our final pipeline looks like.
Building the UI
Ok so now that's out of the way. Lets get started on our React.js frontend-I am kidding. We don't use that here. Anyways lets actually get started on our streamlit app. Its actually quite straightforward.
# continue from before
st.title("RAG Bot")
# Initialize chat history
if "messages" not in st.session_state:
st.session_state.messages = []
# Display chat messages from history on app rerun
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# Accept user input
if prompt := st.chat_input("What is up?"):
# Add user message to chat history
st.session_state.messages.append({"role": "user", "content": prompt})
# Display user message in chat message container
with st.chat_message("user"):
st.markdown(prompt)
with st.chat_message("assistant"):
response_stream = response_generator(st.session_state.messages[-1]['content'])
response = st.write_stream(response_stream)
st.session_state.messages.append({"role": "assistant", "content": response})Now go ahead and run your app using streamlit run [app.py](http://app.py) and see your app in action on your browser.
Resources
- Build a basic LLM chat app - Streamlit Docs
- Langchain documentation
- Cohere documentation