Making a PDF searchable with Langchain
on this page
Introduction
In today's fast-paced digital world, where information overload is a constant challenge, making data searchable has become a vital necessity. Traditional static PDF documents, while widely used for their portability and consistency, often present a significant drawback: the inability to efficiently locate specific information within them. Imagine trying to find a crucial piece of data buried deep in a lengthy research report or a legal document without any search functionality - a daunting and time-consuming task. However AI can help us here. Lets see how we can implement complex search in a pdf with LangChain. In order to make our pdf searchable, we can leverage the concept of embeddings, and vectors. Lets break it down into steps.
What is LangChain?
LangChain is a framework that enables developers to design applications powered by large language models(LLMs). It consists of many integrations to different LLMs, platforms, libraries, and services, and provides a clean abstraction over these complicated mathematical concepts.
Processing the data
- Extract all text from our PDF/document.
- Break this PDF into chunks of an arbitrary size.
- For citation purposes, we also associate with each chunk its page number.
- We can also optionally choose to apply any preprocessing to these chunks as per specific user requirements.
def pdf_to_documents(path : str, chunk_length : int , overlap: int = 0, preprocess = None) -> list[Document]:
'''
Convert PDF document to text chunks with page numbers.
Each chunk has a specified length and is prepended with the page number.
'''
pdf_file = open(path, 'rb')
pdf_reader = PyPDF.PdfReader(pdf_file)
total_pages = len(pdf_reader.pages)
chunks = []
for page_num in tqdm(range(total_pages)):
page = pdf_reader.pages[page_num]
page_text = page.extract_text()
# Split the page text into chunks of specified length
for i in range(0, len(page_text), chunk_length - overlap):
chunk = page_text[i:i+chunk_length]
if preprocess:
chunk = preprocess(chunk)
if chunk:
chunks.append(
Document(
page_content=chunk,
metadata={
'page_num' : page_num + 1,
}))
pdf_file.close()
return chunksWe now have our text in the format we need to work with it.
Vectors Spaces, and Embeddings.
The math
Now we have all our chunks, we need an efficient way of computing how similar two sentences(or chunks) are. Lets assume a black box function computeSimilarity(sentence1, sentence2) which returns a score denoting how similar two sentences are in semantics.
Let our query be “What is a neural network?”. We could compare this query with all of the chunks and get the chunk with the highest similarity score with our query.
Lets improve this method by introducing vectors. We will assume another black box function computeVector(sentence). This is a special function capable of expressing the semantics of a sentence in numbers(or a vector). We will apply this function to each chunk, and we will get a collection of vectors also known as a vector space. And the function computeVector is a special type of function or model called Embeddings. The interesting part about this vector space is that, the vectors closer to each other, the chunk associated to those vectors are close in semantics. This means we can effectively treat the distance between these vectors as a similarity score.
That is enough about the math now. We dont really have to implement any of this or even completely understand it. A high level understanding is enough as this has already been implemented by various frameworks, and libraries very well and efficiently.
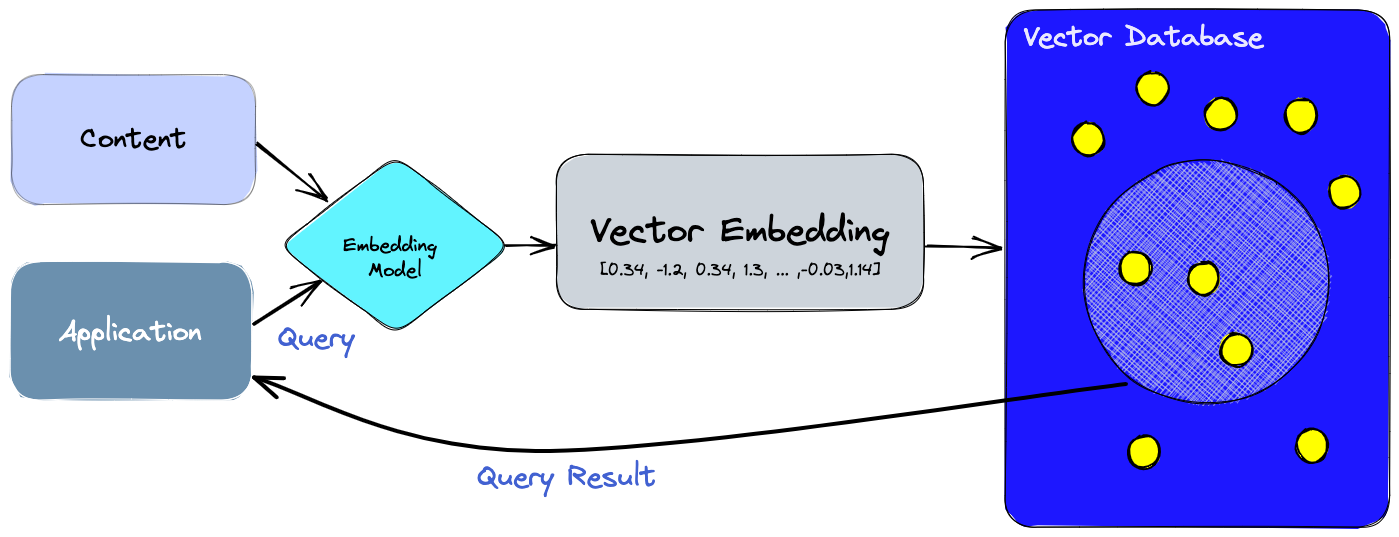
Initializing the Chroma Instance
We will use the ChromaDB module in LangChain to initialize a Vector database. It basically implements everything we have discussed above.
We will use sentence-bert model from hugging face for the embeddings.
sbert = HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2")vectordb = Chroma(
embedding_function = sbert,
persist_directory = 'chroma_store'
)
vectordb.persist()In this snippet, we have initialized an in-memory Chroma vector database, and also configured it to persist to the disk space.
Adding the vectors
Now we will add all our chunks that we extracted earlier, and add them to our vector database. Internally, Chroma is using sentence-bert embeddings to compute a vector of the given chunk or document, and then storing it in the database.
for doc in tqdm(result):
vectordb.add_documents([doc])Querying the database
For demonstration purposes, a research paper 'Attention is all you need' was processed using this code, and made searchable. Upon querying the database, "What optimization technique is used?", the database returns the correct page number along with the text defining the technique.
docs = vectordb.similarity_search(query="What optimization technique is used?", k=2)
for doc in docs:
print(doc)Question Answering with GPT
To improve the output of our program, we can use one of the many available GPT integrations. We will be using the AzureOpenAI LLM integration in LangChain, but you may use any other LLMs available here.
qa_chain = RetrievalQA.from_chain_type(
llm = AzureOpenAI(deployment_name="Text-Davinci"),
retriever=vectordb.as_retriever(search_kwargs={'k': 3}),
return_source_documents=True
)Here we have initialized a LangChain RetrievalQA Chain object that we will use for the question answering. The vector database has been passed to it for document retrieval, and the Text-Davinci LLM from OpenAI is used.
Now if we ask it any questions, it will provide more human readable, and structured answers, as well as the source documents(along with page numbers) for citation.
out = qa_chain({'query': 'What optimization technique is used in the paper?'})
"""
{'query': 'What optimization technique is used in the paper?',
'result': ' The paper uses the Adam optimizer with β1= 0.9, β2 = 0.98 and ϵ= 10−9.',
'source_documents': [Document(page_content='he paper, each training step took about 0.4 seconds. We\ntrained the base models for a total of 100,000 steps or 12 hours. For our big models,(described on the\nbottom line of table 3), step time was 1.0 seconds. The big models were trained for 300,000 steps\n(3.5 days).\n5.3 Optimizer\nWe used the Adam optimizer [ 17] withβ1= 0.9,β2= 0.98andϵ= 10−9. We varied the learning\nrate over the course of training, according to the formula:\nlrate =d−0.5\nmodel·min(step_num−0.5,step _num·warmup _steps−1.5) (3)\n', metadata={'page_num': 7}),
Document(page_content='by one position, ensures that the\npredictions for position ican depend only on the known outputs at positions less than i.\n3.2 Attention\nAn attention function can be described as mapping a query and a set of key-value pairs to an output,\nwhere the query, keys, values, and output are all vectors. The output is computed as a weighted sum\nof the values, where the weight assigned to each value is computed by a compatibility function of the\nquery with the corresponding key.\n3.2.1 Scaled Dot-Product A', metadata={'page_num': 3}),
Document(page_content='s, where the weight assigned to each value is computed by a compatibility function of the\nquery with the corresponding key.\n3.2.1 Scaled Dot-Product Attention\nWe call our particular attention "Scaled Dot-Product Attention" (Figure 2). The input consists of\nqueries and keys of dimension dk, and values of dimension dv. We compute the dot products of the\n3', metadata={'page_num': 3})]}
"""The code for this is available as a Colab notebook here.
Exercise for reader
Now that you've completed the tutorial on making PDFs searchable using LangChain, it's time to enhance the program further with some exciting exercises!
- Meaningful Preprocessing: The program we developed lacks meaningful preprocessing, treating all text the same way. Challenge yourself to implement smart preprocessing techniques to handle different text types, such as table of contents, citations, and references. This will improve the accuracy and relevance of search results.
- Beyond Text Extraction: PDFs often contain images, tables, and graphics. Extend the program's capabilities to not only extract text but also index and search content from images and tables using advanced techniques like image embeddings. Embrace the challenge of making all elements within the PDF searchable and accessible.
Remember, these exercises will elevate your PDF processing skills and make your documents even more intelligent and user-friendly. Happy coding, and have fun exploring the endless possibilities with LangChain!
Conclusion
In this article, we explored how to make PDFs searchable using LangChain. We learned about the power of embeddings and vectors, enabling us to efficiently locate specific information in documents. By leveraging LangChain's ChromaDB module and the "sentence-bert" model, we built an efficient vector database for indexing and querying. Additionally, we discussed the potential for advanced techniques like image embeddings and GPT integration to enhance document processing further. With LangChain, the possibilities are limitless, and you can now unlock the full potential of AI-driven solutions in document management and beyond. Happy exploring!