Local LLMs: Lightweight LLM using Quantization

on this page
Introduction
Can't run that 40gb llama LLM locally? Fear not, there is a solution. It's called quantization. “What's quantization, Mahad”, you say? I promise its very simple and it has nothing to do with quantum mechanics or anything complex.
Background
Usually when you try to load up a large model, let's say 20 GB for instance, then unless you have at least that much RAM available you simply cannot run that model. Because In order to run a model, its weights need to be loaded into memory. So, some scientists realized this problem and thought about ways to reduce the amount of memory needed. They figured out that by sacrificing a little bit of accuracy, we can significantly reduce the model size.
How does it work?
Sounds pretty magical right? Its actually very simple. Usually each model weight parameter is a float, and they can take a lot of space individually. from 16-64 bits depending on float precision. But what if we somehow compressed all the weights such that they can be represented in 8 bits, or even less!
Dreaded terminology alert! 8-bit quantization is called Q8, and 7-bit Q7 and so on. As you can imagine the lower you go, the more inaccurate your model becomes. This is because this compression is lossy. You are losing some information in return for smaller size. Ok we get that, but how does this magical compression work? Well even that part is surprisingly simple.
We basically want to map the entire range of the model's weights (min and max) to our possible range expressible in 8 bits for instance (-128 to 127)
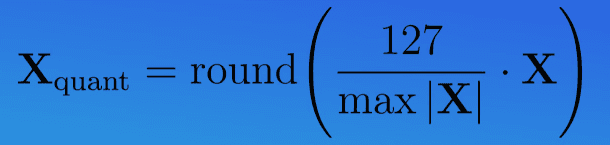
Its ok if you don't completely understand this, but the main point is that now your weights will be in the 8 bits range but still perform roughly similar. Also, there are many other ways and formulas to quantization, but the concept remains the same.
LLama-cpp-python & HuggingFace
So what's the point of all this? The next time you are looking for models on hugging face, look for quantized ones. An easy identifier is the repo name ending with GGUF or GGML or GPTQ like here. You can see that there are several variations of the model available ranging from Q4 to Q8. You can easily run this using the llama-cpp-python project.
from llama_cpp import Llama
llm = Llama.from_pretrained(
repo_id="lmstudio-community/DiscoPOP-zephyr-7b-gemma-GGUF",
filename="DiscoPOP-zephyr-7b-gemma-Q4_K_M.gguf"
)
llm.create_chat_completion(
messages = [
{"role": "system", "content": "You are a math tutor."},
{
"role": "user",
"content": "Hello. Can you help me with my math problem? what is 2 + 2 :(."
}
]
)Conclusion
So, in this article we looked at:
-
What is quantization?
We explored how quantization compresses model weights into smaller bit representations, like 8-bit integers, to reduce memory usage without sacrificing too much performance.
-
Why do I care about it?
Understanding the importance of quantization for running large models on hardware with limited memory capacity.
-
Ok I'm hooked, but how does it work though? (Boring Math alert!!)
We looked into the technical details, discussing how quantization maps the range of model weights to fit within smaller bit ranges, ensuring the model remains functional while being more memory efficient.
-
Ok cool, but how do I actually use this?
Practical steps were outlined for using quantized models, such as identifying them on platforms like Hugging Face (look for GGUF, GGML, or GPTQ labels) and implementing them with tools like
llama-cpp-python.